
近日,我们推出了企业级人工智能服务FactVerse AI(简称FAI),旨在用于探索、开发和实施基于人工智能的数字孪生技术。FAI的核心组成部分是LLM(基础语言模型)、优化器(对基础LLM进行调优和修改以满足特定行业或应用领域的需求)、Agent(FactVerse多模态交互接口),提供一系列生成式AI工具与服务,可以广泛应用于各种数字孪生场景。
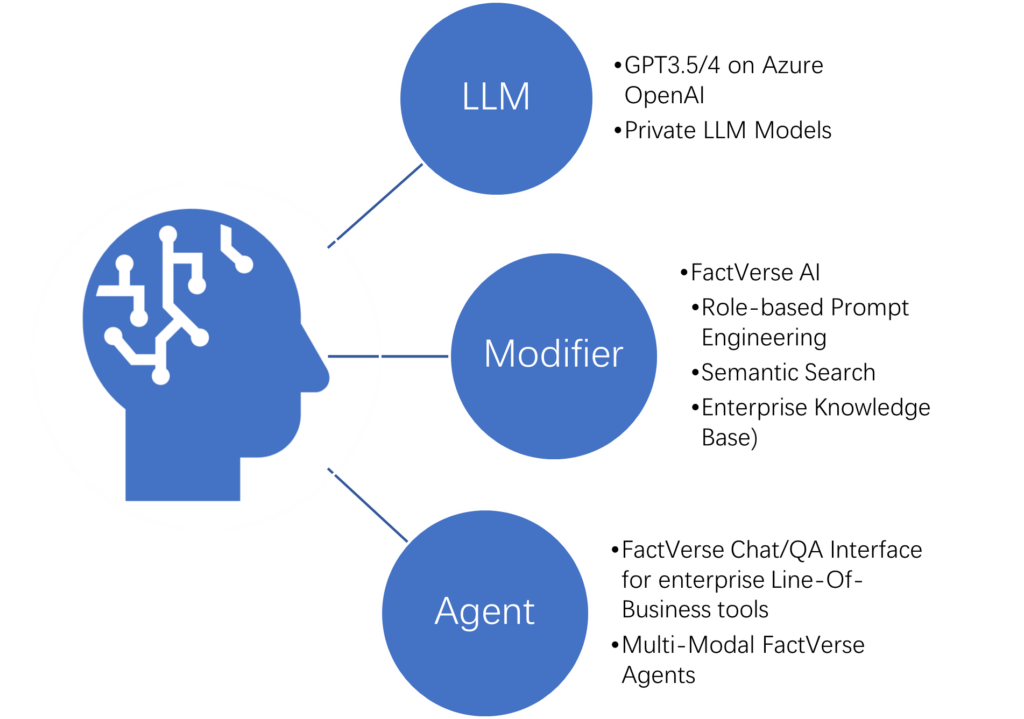
FactVerse AI 背后的技术形成
大语言模型(LLM)
关于LLM的论述已经有很多,其原理在这里我们就不再重复了。虽然LLM在定义上只是语言模型,但因为其训练规模巨大,LLM在海量自由文本中学到了大量的知识,从而使得LLM拥有了许多隐藏的能力,让人们看到了“通用人工智能”的影子。在FAI中,我们就是把LLM看做通用AI模型,以LLM为基石,构建一系列的周边工具系统,挖掘LLM的隐藏能力,让它能够解决各种使用场景中的特定问题。能够解决各种问题,才是企业服务所需要的。
优化器(Modifier)
如何挖掘LLM的隐藏能力,就要靠优化器了。优化器是我们自己内部的一种分类方式,并不只是一项特定的技术,而是多种技术的灵活组合。优化器(Modifier)在FactVerse AI中扮演着至关重要的角色。它是连接大语言模型和执行代理的关键桥梁,以最大限度地挖掘和利用LLM的能力,从而使执行代理能够满足多样化的业务需求。简单来说,优化器就是让AI变得更加聪明,更能理解和适应具体任务。FAI中的优化器技术大致上可以划分为几类:
提词工程(Prompt Engineering):这是一种通过设计和选择恰当的输入语句(即“提词”)来引导LLM生成期望的输出的技术。通过不同的提词,可以限定LLM回答问题的范围、方式等,挖掘出LLM的各种能力。
基于知识查询的长期记忆:LLM是通用语言模型,它内置的只是通用知识,对于特定领域的问题,LLM可能无法给出准确的答案。这时候,就需要利用知识库将特定领域的文档和问答灌入系统,在向量数据库或搜索系统中形成“长期记忆”,生成时将相关记忆注入到提词中,使LLM能够回答特定领域的问题。
基于预训练LLM的调优(Fine-Tuning):当提词工程和知识库类的长期记忆补充还不能满足需求时,可以考虑采用调优技术。调优是真正的再训练,虽然很难引入新的知识和逻辑能力,但却能切实地改变LLM的输出状态和风格,让LLM能够更好地契合垂直领域。
FactVerse多模态交互接口(Agent)
有了大语言模型和优化器,FactVerse AI已经算是拥有了大脑,但真正想要让AI来解决实际业务问题,我们还需要针对各种应用场景的使用端,这就是FactVerse多模态交互接口。Agent是用来解决实际问题的,这就注定了代理的多样性。未来FactVerse AI会提供一系列的交互接口,同时也具备可扩展性(你可以看做类似ChatGPT Plugin的逻辑),针对特定场景定制专用接口。主要分为两大部分:
对话交互(虚拟人):一种直接的方式,让用户能够与FacVerse AI进行互动。FAI提供了一套虚拟人提词模板,这些模板描述了企业中常见的岗位角色,用户可以在创建虚拟人时指定岗位,使得虚拟人能以相应岗位的风格进行对话。用户也可以自定义提词模板来创建特定岗位的虚拟人。此外,虚拟人还可以搭载不同的知识库,从而获得专业领域的知识。基于数字孪生技术,用户可以赋予虚拟人三维形象,并在数字孪生场景中进行交互。
内容生成:一种强大的生产力工具。用户在构建数字孪生体\场景的时候,可以随时利用FactVerse AI生成文本、语音、图像(目前已经实现),未来还会生成视频、3D模型等。另外,FAI还会逐渐支持FactVerse工具链中的特有功能,一些复杂性的、重复性的工作,可以逐渐交由FAI来完成,例如一键生成展示剧本,按照描述自动生成数字孪生体行为逻辑脚本等等,拥有巨大的想象空间。
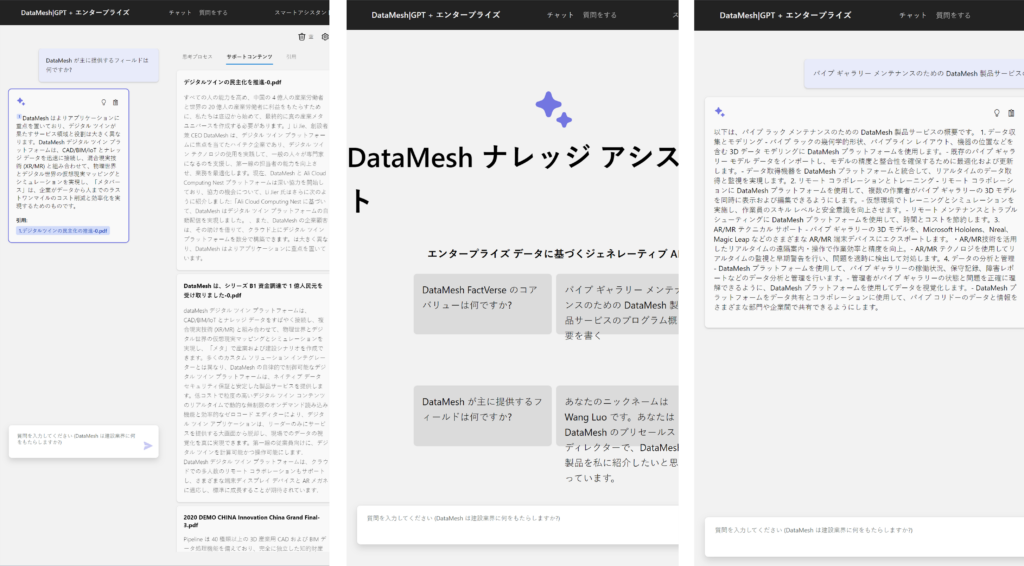
通过大语言模型、优化器和Agent的协同工作,FactVerse AI 将人工智能与数字孪生技术结合的可能性发挥到极致,重新定义了GPT时代下的数字孪生。